프로젝트에서 Kudu를 쓸 기회가 생겨서 간단하게 특징을 정리해보기로 하겠습니다. Cloudera 위에서 Kudu-Impala를 약간 써본 관계로, 전체적인 내용보다는 특징적인 부분만을 정리해보려고 합니다.

# Kudu의 특징
- Apache Hadoop 플랫폼 환경에서 사용되는 Columnar 스토리지 엔진이다.
- 데이터웨어하우징 워크로드에서 유리함
- MapReduce, Spark 및 기타 Hadoop ecosystem 컴포넌트와 통합된다.
- 엄격한 직렬화 일관성을 포함하여 일관성 유지를 위한 다양한 옵션을 제공한다.
- Raft Consensus 알고리즘을 사용하여 높은 가용성을 유지한다. 반수 이상의 Replica가 Available하다면 Tablet Server는 Read/Write를 수행할 수 있다.
- 구조화된 모델(Structured Data Model)
# Kudu의 구조
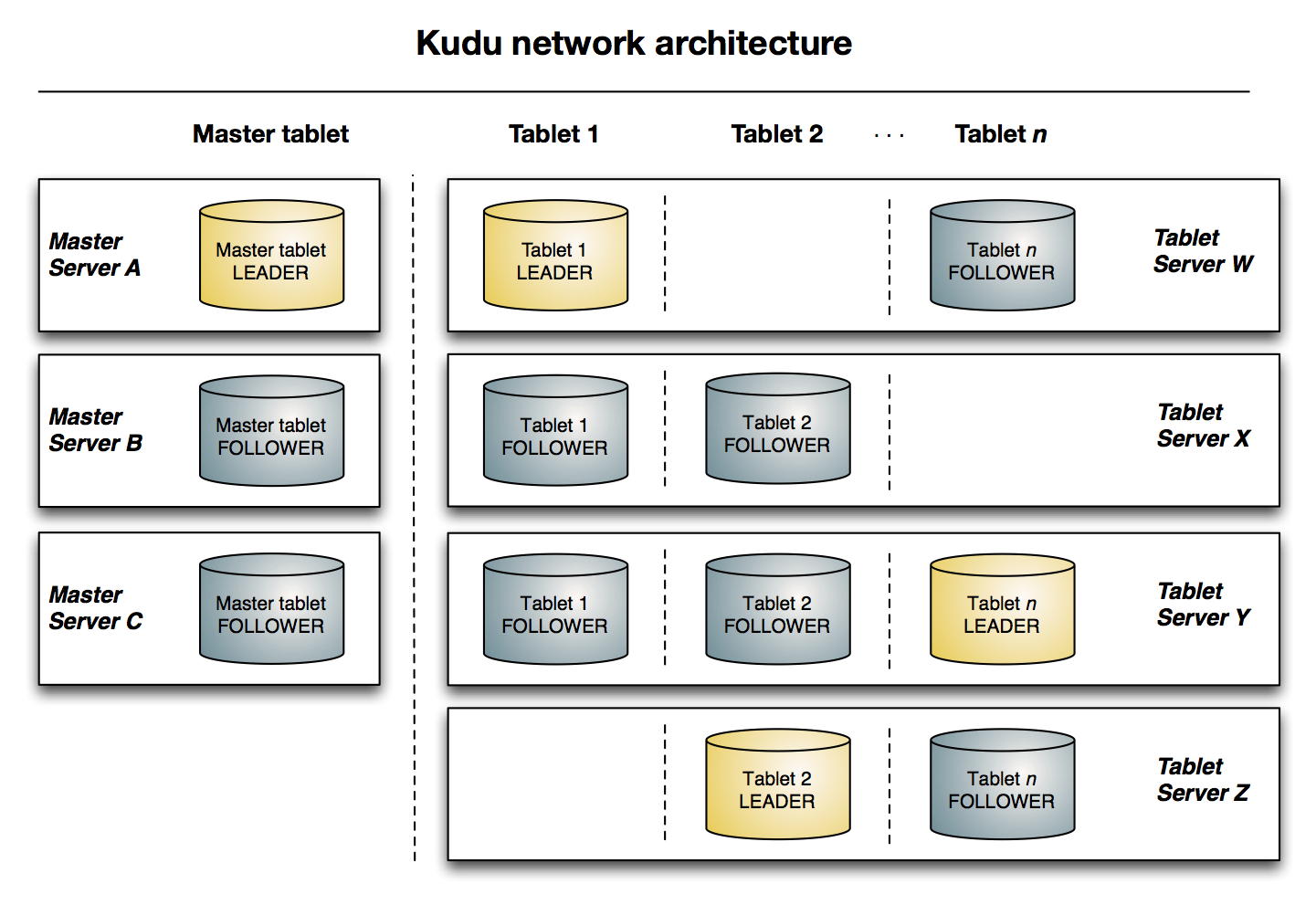
Table : 데이터가 저장되는 공간. Table은 Schema 정렬된 Primary Key를 가진다. Table은 Tablet이라는 세그먼트로 분할된다.
Tablet : Table의 연속 세그먼트. Tablet은 여러 Tablet Server에 ReplicaSet를 구성함
Tablet Server : Tablet을 저장하고 클라이언트에 저장하는 역할을 한다. Raft Consensus 알고리즘을 사용하여 리더를 선출하고 읽기 혹은 쓰기 요청을 처리한다.
Master : Tablet, Tablet Server, Catalog Table 및 클러스터와 관련한 Metadata를 가진다. 현재 Leader가 사라지면 Raft Consensus 알고리즘을 이용하여 새로운 Master가 선출된다.
또한 Master는 새로운 Table에 대한 metadata를 Catalog Table에 쓰거나 Tablet Server들에 Tablet을 생성하는 프로세스를 조정하는 등의 metadata 오퍼레이션을 수행한다.Table Server들은 셋팅된 Interval에 따라 Master에 heartbeat를 전송한다.
# Kudu-Impala 테이블 생성
Internal & External Impala Table
Internal :
- Impala에 의해 관리되며
- Impala에서 삭제하면 데이터와 테이블이 완전 삭제됨.
- Impala를 사용하여 새 테이블을 만들면 일반적으로 내부 테이블
External :
Create External Table로 생성할 수 있으며
테이블을 삭제해도 Kudu에서 테이블이 삭제되지 않고, Impala와 Kudu 간 매핑만 제거함.
Kudu API 또는 Apache Spark 등에서 만들었을 경우 Impala에서 자동으로 표시되지 않기 때문에, 먼저 Impala에서 External 테이블을 만들어 Kudu 테이블과 Impala 데이터베이스를 매핑해야 함.
12345CREATE EXTERNAL TABLE my_mapping_tableSTORED AS KUDUTBLPROPERTIES ('kudu.table_name' = 'my_kudu_table');
Impala에서 새로운 Kudu 테이블 만들기
테이블 생성
12345678910111213141516--일반적인 생성구문CREATE TABLE my_first_table(id BIGINT,name STRING,PRIMARY KEY(id))PARTITION BY HASH PARTITIONS 16STORED AS KUDU;-- CTASCREATE TABLE new_tablePRIMARY KEY (ts, name)PARTITION BY HASH(name) PARTITIONS 8STORED AS KUDUAS SELECT ts, name, value FROM old_table;※ Kudu는 현재 (2017.11) 자동/수동 Sharding 매커니즘이 없기 때문에, 테이블을 만들 때
partition by절을 이용하여 분할 Key를 지정해야 한다.
파티션 설정
PARTITION BY RANGE: 범위 파티션을 지정할 수 있으며, 아래와 같이 사용함.1234567891011121314151617181920212223242526CREATE TABLE cust_behavior (_id BIGINT PRIMARY KEY,salary STRING,edu_level INT,usergender STRING,`group` STRING,city STRING,postcode STRING,last_purchase_price FLOAT,last_purchase_date BIGINT,category STRING,sku STRING,rating INT,fulfilled_date BIGINT)PARTITION BY RANGE (_id)(PARTITION VALUES < 1439560049342,PARTITION 1439560049342 <= VALUES < 1439566253755,PARTITION 1439566253755 <= VALUES < 1439572458168,PARTITION 1439572458168 <= VALUES < 1439578662581,PARTITION 1439578662581 <= VALUES < 1439584866994,PARTITION 1439584866994 <= VALUES < 1439591071407,PARTITION 1439591071407 <= VALUES)STORED AS KUDU;PARTITION BY HASH: HASH 값으로 파티셔닝하며, column을 지정하지 않으면 모든 기본 키 열을 해싱하여 원하는 수의 버킷을 생성할 수 있다.값이 단조롭게 증가하는 열에서 범위별로 파티션을 나누면 마지막 Tablet이 다른 테이블보다 훨씬 커지므로 주의할 것.
PARTITION BY HASHandRANGE: 다음과 같은 형태로 복합 파티션 키를 설정할 수 있음.12345678910111213141516171819202122232425CREATE TABLE cust_behavior (id BIGINT,sku STRING,salary STRING,edu_level INT,usergender STRING,`group` STRING,city STRING,postcode STRING,last_purchase_price FLOAT,last_purchase_date BIGINT,category STRING,rating INT,fulfilled_date BIGINT,PRIMARY KEY (id, sku))PARTITION BY HASH (id) PARTITIONS 4,RANGE (sku)(PARTITION VALUES < 'g',PARTITION 'g' <= VALUES < 'o',PARTITION 'o' <= VALUES < 'u',PARTITION 'u' <= VALUES)STORED AS KUDU;Non-Covering Range Partitions : Kudu 1.0 이상에서 다음과 같은 Range 파티션을 만들 수 있다.
123456789101112CREATE TABLE sales_by_year (year INT, sale_id INT, amount INT,PRIMARY KEY (sale_id, year))PARTITION BY RANGE (year) (PARTITION VALUE = 2012,PARTITION VALUE = 2013,PARTITION VALUE = 2014,PARTITION VALUE = 2015,PARTITION VALUE = 2016)STORED AS KUDU;이 테이블은 2017이 되면 입력이 거부되기 때문에, 다음과 같이 range가 추가되어야 한다.
1ALTER TABLE sales_by_year ADD RANGE PARTITION VALUE = 2017;마찬가지로, range partition은 drop될 수 있다.
1ALTER TABLE sales_by_year ADD RANGE PARTITION VALUE = 2017;
테이블 속성 변경
Internal 테이블인 경우,
kudu.table_name속성을 변경하여 기본 Kudu 테이블 이름 변경12ALTER TABLE my_internal_tableSET TBLPROPERTIES('kudu.table_name' = 'new_name')다른 응용 프로그램이 Impala에서 Kudu 테이블의 이름을 바꾼 경우 외부 테이블 다시 매핑
12ALTER TABLE my_external_table_SET TBLPROPERTIES('kudu.table_name' = 'some_other_kudu_table')Kudu Master 주소 변경
12ALTER TABLE my_tableSET TBLPROPERTIES('kudu.master_addresses' = 'kudu-new-master.example.com:7051');Internal -> External로 변경
1ALTER TABLE my_table SET TBLPROPERTIES('EXTERNAL' = 'TRUE');## 참고
Introducing Apache Kudu(https://kudu.apache.org/docs/)